보통 인덱스를 설명할 때 자주 드는 예시가 영어사전의 색인이다. 영어사전에서 단어를 찾을 경우 찾고자 하는 단어를 찾을 때까지 영어사전을 처음부터 뒤지는 것이 아니라 banana 라고 한다면 b로 시작하는 단어부터 찾는다.
sql을 공부하다 보면 인덱스를 사용하면 조회의 성능이 향샹된다는 말을 자주 들을 것이다. 그렇다면 인덱스를 사용하면 왜 조회 성능이 향상되는 것일까?
인덱스는 컬럼을 복사한 뒤 오름차순이나 내림차순으로 정렬해 별도의 저장공간에 저장해둔다.
이렇게 하면 컬럼이 정렬되어 있기 때문에 이진 탐색을 할 수 있고 그러면 FULL SCAN을 하는 것보다 조회 시 성능이 향상되게 된다. 하지만 인덱스는 별도의 저장공간을 추가로 사용하며 인덱스를 생성해둔 테이블의 내용이 바뀌면 인덱스도 동일하게 유지시켜 주어야 하기 때문에 데이터의 수정, 삭제 연산이 발생 할 경우 INDEX테이블과 원본 테이블 모두 수정해 주어야 한다는 단점이 있다. 또한 인덱스는 원본 테이블에서 10% 이하의 데이터를 처리하는 경우에만 효과가 있다고 한다. 하지만 이러한 단점에도 INDEX는 조회시 성능을 향상시킬 수 있기 때무에 매우 많이 사용되고 있다고 한다.
또한 인덱스는 한 테이블에 여러 개를 생성 할 수도 있고 한번의 인덱스에 여러 컬럼을 지정해 생성할 수 도 있다고 한다. 하지만 하나의 테이블에 여러 인덱스를 지정하는 것은 오히려 성능의 저하를 일으킬 수 있다고 하니 한 테이블당 1~2개가 적당하다고 한다.
기본적으로 생성되는 INDEX : PK
데이터베이스 테이블을 만들게 되면 대부분 PK를 지정한다. PK는 자동적으로 테이블을 생성 할 때 INDEX가 만들어 지고 이름을 자동으로 부여된다고 한다.
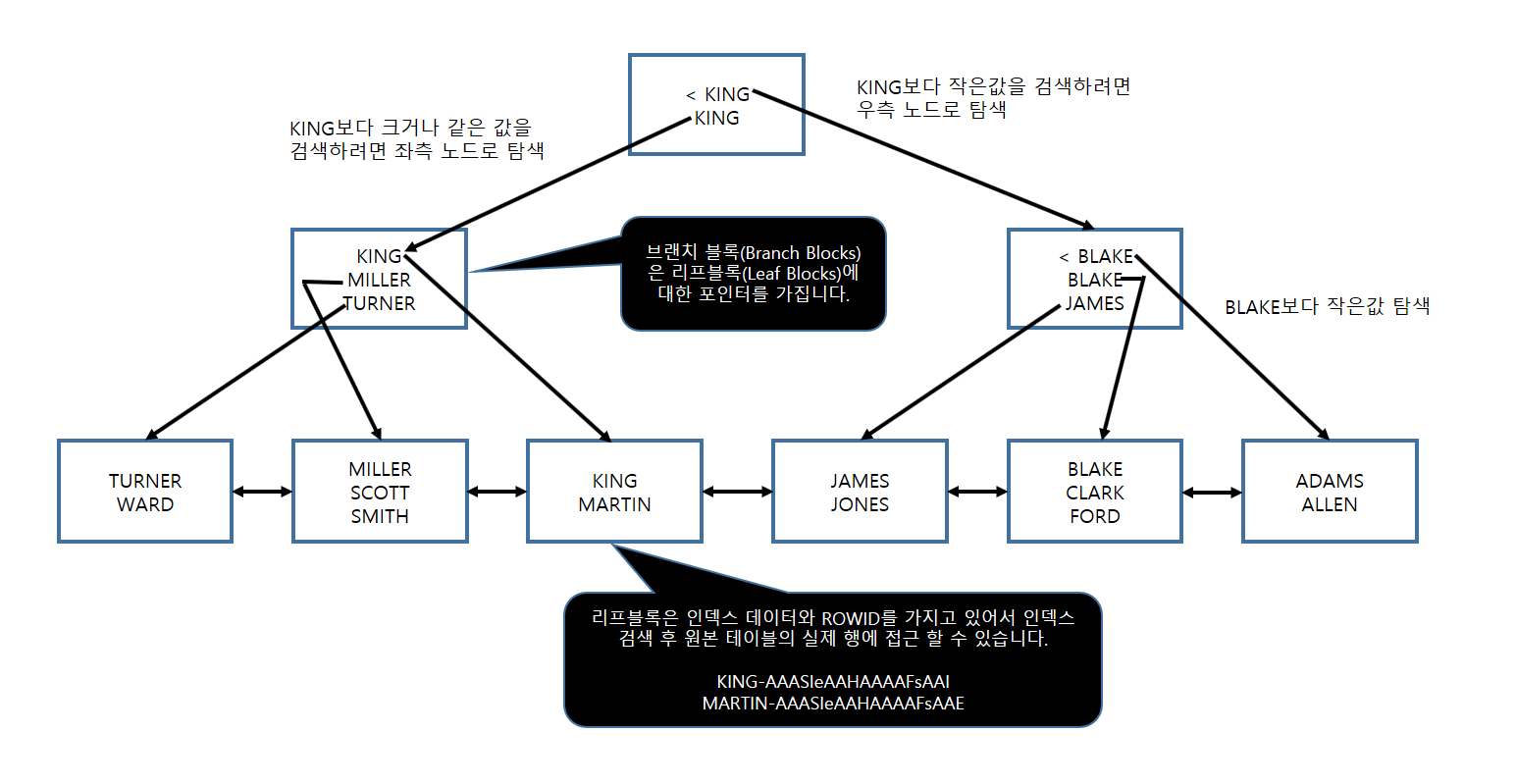
인덱스를 생성하게 되면 대부분의 경우 위 그림처럼 B * tree가 생성되게 된다. 맨 위의 노드를 root라고 하고 가이드를 제공해 주는 노드를 branch라고 하며 인덱스로 지정한 컬럼의 값과 원본 테이블의 rowid를 가지고 있는 노드가 정렬된 채로 맨 마지막에 양방향연결리스트로 연결되어져 있다. 가장 밑단의 노드들을 리프노드라고 한다.
만약 인덱스로 지정한 컬럼의 값이 null이면 인덱싱 되지 않거나 오름차순 정렬 시 가장 마지막에 올 수 있다고 한다.
결론
b - tree 인덱스는 10% 정도 미만의 작은 집단을 조회하는 경우에만 사용하고 그 이상의 집단을 자주 조회할 경우에는 비트맵 인덱스를 사용하는 것이 좋다고 한다. 또한 테이블의 크기가 작을 경우에는 자동으로 생성되는 pk인덱스 외에 별도의 인덱스를 지정해 줄 필요가 없으며 b - tree 인덱스가 2개 이상의 컬럼으로 이루어 져 있을 경우 자주 조회되고 unique한 값을 가지는 컬럼을 앞에 위치시켜 놓는 것이 좋다.
참고
'데이터베이스' 카테고리의 다른 글
| [데이터베이스] ROLLUP() (0) | 2023.07.12 |
|---|---|
| [데이터베이스] 서브쿼리 종류 (0) | 2023.07.05 |
| [데이터베이스] 오라클 RONUM (0) | 2023.07.04 |
| [데이터베이스] 오라클 WITH절 사용방법 (0) | 2023.07.03 |
| [데이터베이스]INTERSECT 키워드, CROSS JOIN (0) | 2023.06.30 |
